
In this tutorial, I will guide you through the process of running Selenium with ChromeDriver inside an AWS Lambda function. This setup is useful for automating web scraping tasks, testing web applications, or performing any browser automation tasks on the cloud. By containerizing our application and deploying it to AWS Lambda, we ensure a scalable and serverless architecture. Let’s dive into the details.
What We’re Doing
We will create a Docker container that includes all the necessary dependencies for running Selenium and ChromeDriver. This container will be deployed as an AWS Lambda function. The Lambda function will perform a simple task: searching for “OpenAI” on Google and returning the titles of the search results.
Prerequisites
Before we start, make sure you have:
- An AWS account
- A GitHub account
- Docker Desktop installed
- AWS CLI configured
Before we delve into the topic, we invite you to support our ongoing efforts and explore our various platforms dedicated to enhancing your IoT projects:
- Subscribe to our YouTube Channel: Stay updated with our latest tutorials and project insights by subscribing to our channel at YouTube — Shilleh.
- Support Us: Your support is invaluable. Consider buying me a coffee at Buy Me A Coffee to help us continue creating quality content.
- Hire Expert IoT Services: For personalized assistance with your IoT projects, hire me on UpWork.
ShillehTek Website (Exclusive Discounts):
https://shillehtek.com/collections/all
ShillehTekAmazon Store:
ShillehTek Amazon Store — Canada
ShillehTek Amazon Store — Japan
The Project Files
1. main.py
This Python script is the Lambda function that uses Selenium to perform browser automation.
import os
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options as ChromeOptions
from tempfile import mkdtemp
def lambda_handler(event, context):
chrome_options = ChromeOptions()
chrome_options.add_argument("--headless=new")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--disable-dev-tools")
chrome_options.add_argument("--no-zygote")
chrome_options.add_argument("--single-process")
chrome_options.add_argument(f"--user-data-dir={mkdtemp()}")
chrome_options.add_argument(f"--data-path={mkdtemp()}")
chrome_options.add_argument(f"--disk-cache-dir={mkdtemp()}")
chrome_options.add_argument("--remote-debugging-pipe")
chrome_options.add_argument("--verbose")
chrome_options.add_argument("--log-path=/tmp")
chrome_options.binary_location = "/opt/chrome/chrome-linux64/chrome"
service = Service(
executable_path="/opt/chrome-driver/chromedriver-linux64/chromedriver",
service_log_path="/tmp/chromedriver.log"
)
driver = webdriver.Chrome(
service=service,
options=chrome_options
)
# Open a webpage
driver.get('https://www.google.com')
# Find the search box
search_box = driver.find_element(By.NAME, 'q')
# Enter a search query
search_box.send_keys('OpenAI')
# Submit the search query
search_box.send_keys(Keys.RETURN)
# Wait for the results to load
time.sleep(2)
# Get the results
results = driver.find_elements(By.CSS_SELECTOR, 'div.g')
# Print the titles of the results
titles = [result.find_element(By.TAG_NAME, 'h3').text for result in results]
# Close the WebDriver
driver.quit()
return {
'statusCode': 200,
'body': titles
}
Explanation:
- chrome_options: Configures Chrome to run headlessly and optimizes it for a containerized environment.
- driver.get: Navigates to Google.
- search_box: Finds the search input, enters “OpenAI”, and submits the form.
- results: Extracts and prints the titles of the search results.
2. Dockerfile
This Dockerfile creates an image with all the dependencies required to run Selenium with ChromeDriver.
FROM amazon/aws-lambda-python:3.12
# Install chrome dependencies
RUN dnf install -y atk cups-libs gtk3 libXcomposite alsa-lib \
libXcursor libXdamage libXext libXi libXrandr libXScrnSaver \
libXtst pango at-spi2-atk libXt xorg-x11-server-Xvfb \
xorg-x11-xauth dbus-glib dbus-glib-devel nss mesa-libgbm jq unzip
# Copy and run the chrome installer script
COPY ./chrome-installer.sh ./chrome-installer.sh
RUN chmod +x ./chrome-installer.sh
RUN ./chrome-installer.sh
RUN rm ./chrome-installer.sh
# Install selenium
RUN pip install selenium
# Copy the main application code
COPY main.py ./
# Command to run the Lambda function
CMD [ "main.lambda_handler" ]
Explanation:
- FROM amazon/aws-lambda-python:3.12: Uses AWS Lambda base image for Python 3.12.
- RUN dnf install -y: Installs the necessary dependencies for running Chrome.
- COPY ./chrome-installer.sh: Copies the Chrome installer script into the image.
- RUN ./chrome-installer.sh: Executes the script to install Chrome and ChromeDriver.
- RUN pip install selenium: Installs the Selenium Python package.
-
COPY main.py: Copies the
main.pyscript into the image. - CMD [ “main.lambda_handler” ]: Specifies the command to run the Lambda function.
3. chrome-installer.sh
This script installs the latest versions of Chrome and ChromeDriver.
#!/bin/bash
set -e
latest_stable_json="https://googlechromelabs.github.io/chrome-for-testing/last-known-good-versions-with-downloads.json"
# Retrieve the JSON data using curl
json_data=$(curl -s "$latest_stable_json")
latest_chrome_linux_download_url="$(echo "$json_data" | jq -r ".channels.Stable.downloads.chrome[0].url")"
latest_chrome_driver_linux_download_url="$(echo "$json_data" | jq -r ".channels.Stable.downloads.chromedriver[0].url")"
download_path_chrome_linux="/opt/chrome-headless-shell-linux.zip"
download_path_chrome_driver_linux="/opt/chrome-driver-linux.zip"
mkdir -p "/opt/chrome"
curl -Lo $download_path_chrome_linux $latest_chrome_linux_download_url
unzip -q $download_path_chrome_linux -d "/opt/chrome"
rm -rf $download_path_chrome_linux
mkdir -p "/opt/chrome-driver"
curl -Lo $download_path_chrome_driver_linux $latest_chrome_driver_linux_download_url
unzip -q $download_path_chrome_driver_linux -d "/opt/chrome-driver"
rm -rf $download_path_chrome_driver_linux
Explanation:
- curl -s: Fetches the latest stable versions of Chrome and ChromeDriver.
- mkdir -p: Creates directories to store the downloaded files.
- unzip -q: Extracts the downloaded files to the specified directories.
Building, Tagging, and Pushing the Docker Image
Build the Docker Image:
docker build -t selenium-chrome-driver .
Tag the Docker Image:
docker tag selenium-chrome-driver <your amazon account id>.dkr.ecr.us-east-1.amazonaws.com/docker-images:v1.0.0
Push the Docker Image to AWS ECR:
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <your amazon account id>.dkr.ecr.us-east-1.amazonaws.com/docker-imagesdocker push <your amazon account id>.dkr.ecr.us-east-1.amazonaws.com/docker-images:v1.0.0
Explanation:
- docker build: Builds the Docker image from the Dockerfile.
- docker tag: Tags the image with a specific version.
- docker push: Pushes the image to the specified AWS ECR repository.
Deploying the Lambda Function
After pushing the image to AWS ECR, you can deploy it using AWS Lambda. Ensure you are logged into AWS and have the necessary permissions.
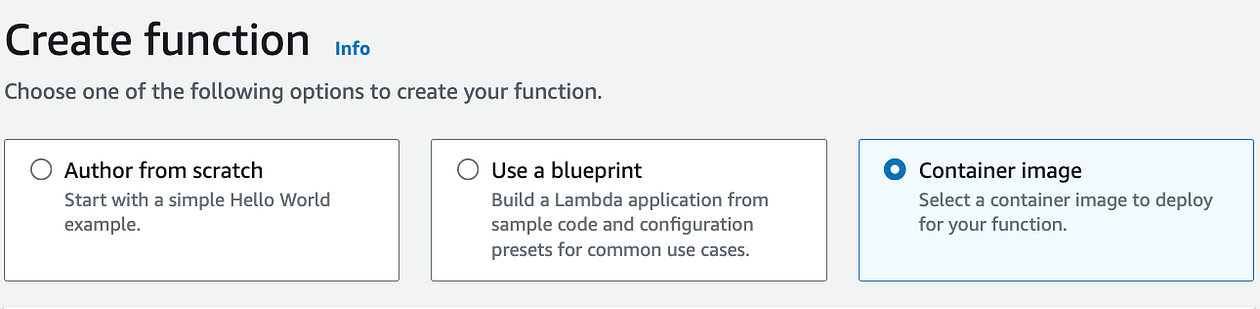
Increase the configuration resources in the container so it does not time out or run out of memory.
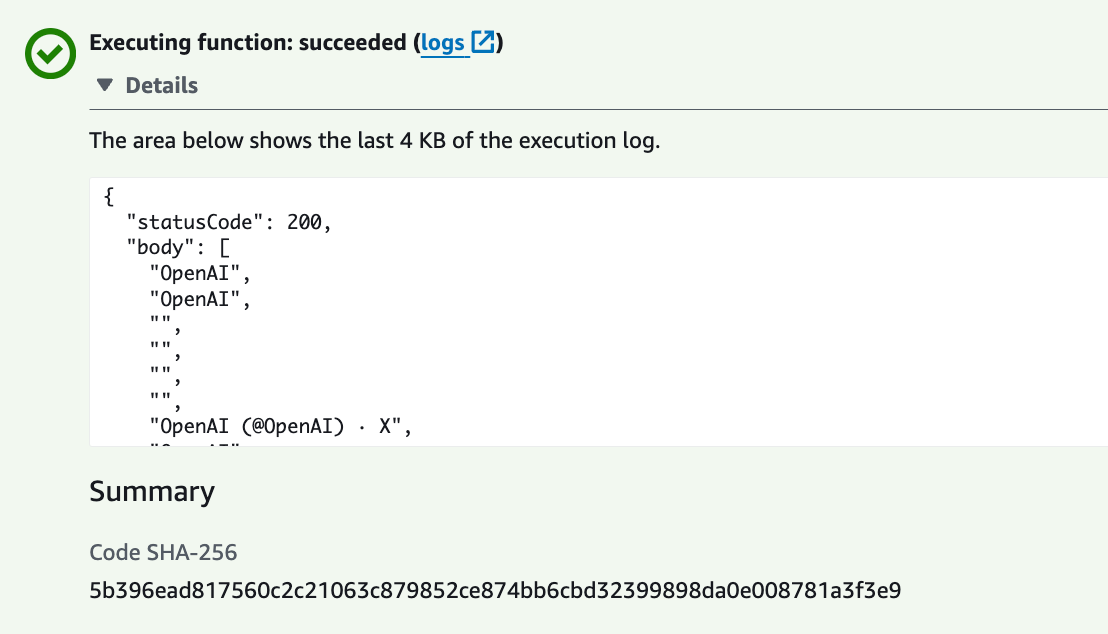
After running a test event we see a successful output! It worked :)
Conclusion
In this article, we walked through the process of setting up Selenium with ChromeDriver in an AWS Lambda function using Docker. This approach allows you to leverage the power of Selenium for browser automation in a serverless environment, ensuring scalability and efficiency. By containerizing the application, you can manage dependencies more effectively and deploy seamlessly to AWS Lambda.
Feel free to experiment and expand this setup for your own browser automation needs. Goodluck, and do not forget to subscribe or support!